Plongements de mots
20/01/2025
1.1 Définition
Techniques pour apprendre à un ordinateur les relations syntaxiques et sémantiques entre les mots d’un corpus de texte.




1.2 Principe et fonctionnement
Données nécessaires à l’entrainement
- Du texte :

- Un dictionnaire :

Jeu de données
Soient :
- une liste de mots \(W = \{w_i\} : i \in \mathbb{N}\)
- une fenêtre glissante \(F(n, i) = \{w_{i-n}, ..., w_{i-2}, w_{i-1}\} \cup \{w_{i+1}, w_{i+2}, ..., w_{i+n}\} : n \in \mathbb{N}\)
- le jeu de données \(D = \{(w_i, F(n,i))\}\)
Exemple :
| Le | chat | mange | la | souris | et | la | souris | le | fromage |
|---|
- \(n = 2\), \(i = 3\)
- le mot : “mange”.
- la fenêtre : “Le”, “chat”, “la”, “souris”
Encodage et représentation des données
Inconvénients des mots sous la forme de chaines de caractères
- taille variable (entre les mots et entre les fenêtres)
- pas de relation sémantique entre les lettres qui forment les mots
- grande complexité computationnelle
Solution : le one hot encoding
Représentation des mots sous la forme de vecteurs à \(n\) dimensions, \(n\) étant la taille du dictionnaire.
Avantages :
- absence de biais dans la représentation des mots
- simplicité de représentation et de calcul
- possibilité d’aplatir les vecteurs de différents mots pour créer un contexte (fenêtre)
Exemple
| Le | chat | mange | la | souris | et | la | souris | le | fromage |
|---|
7 mots différents : vecteurs de taille 7
- le : \([1,0,0,0,0,0,0]\)
- chat : \([0,1,0,0,0,0,0]\)
- mange : \([0,0,1,0,0,0,0]\)
- la : \([0,0,0,1,0,0,0]\)
- souris : \([0,0,0,0,1,0,0]\)
- et : \([0,0,0,0,0,1,0]\)
- fromage : \([0,0,0,0,0,0,1]\)
Couple mot-fenêtre : \(([0,0,1,0,0,0,0], [1,1,0,1,1,0,0])\)
Le modèle
Forme du modèle
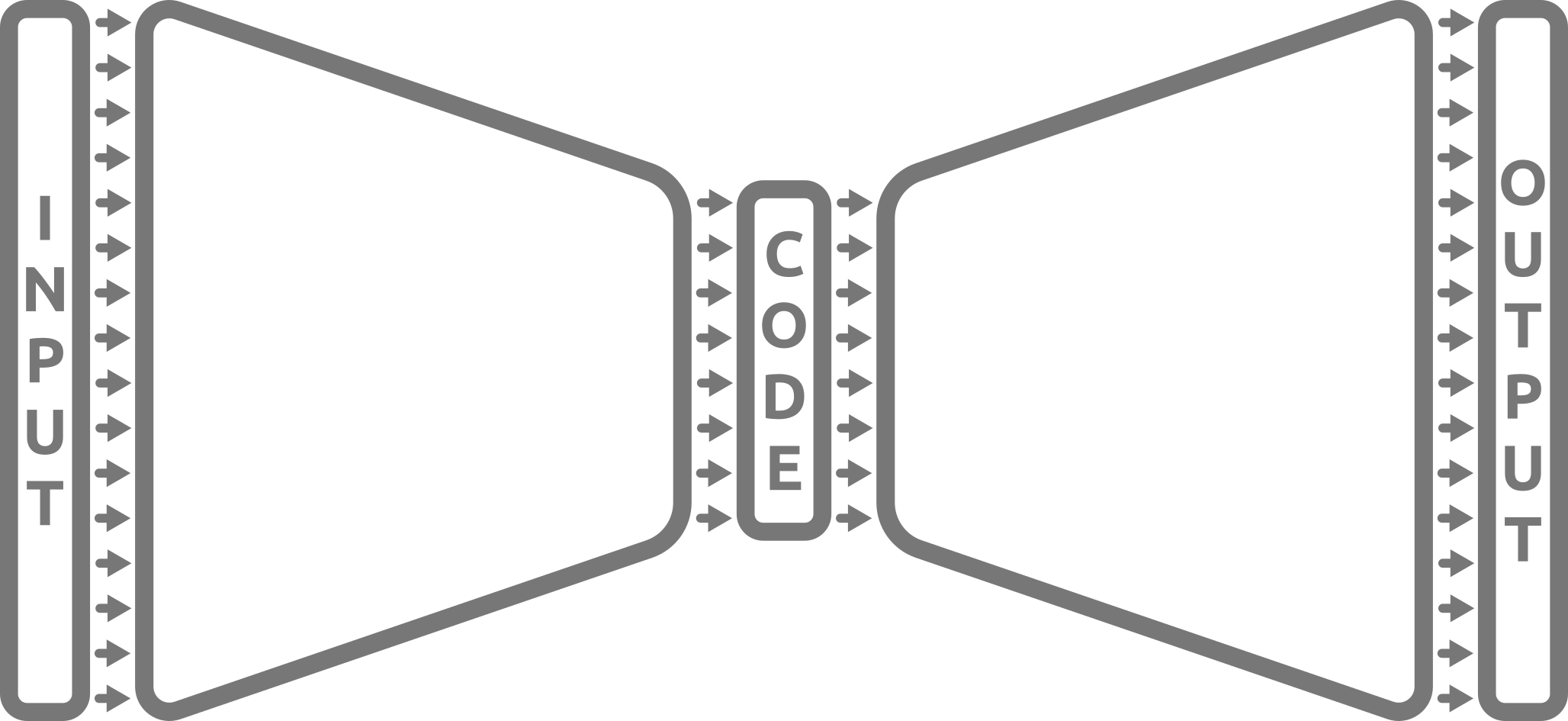
Fonctionnement
- Réduction de dimension des données d’entrée (plongement)
- Prédiction de la sortie à partir de la représentation latente des données d’entrée
- Rétropropagation et correction de l’erreur
Effets de l’apprentissage du modèle
- Apprentissage des relations sémantiques entre les mots
- Représentation des mots porteuse de sens (représentation latente)
- Possibilité de manipuler ces représentations (opérations mathématiques)
Variantes
- CBOW : Prédire un mot à partir de la fenêtre.
- Skip gram : Prédire la fenêtre à partir d’un mot.
1.3 Applications
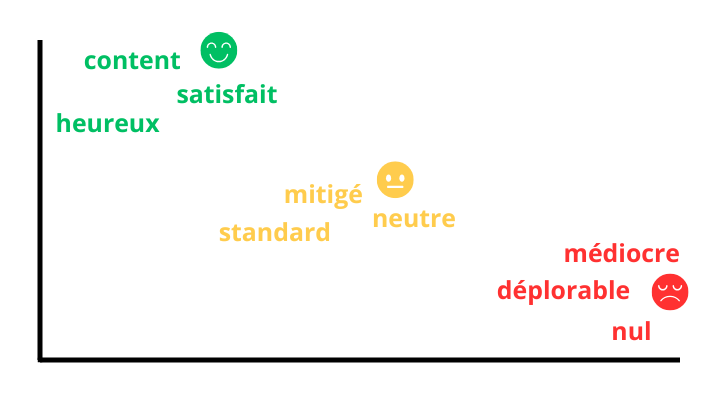
Classification et analyse de sentiments
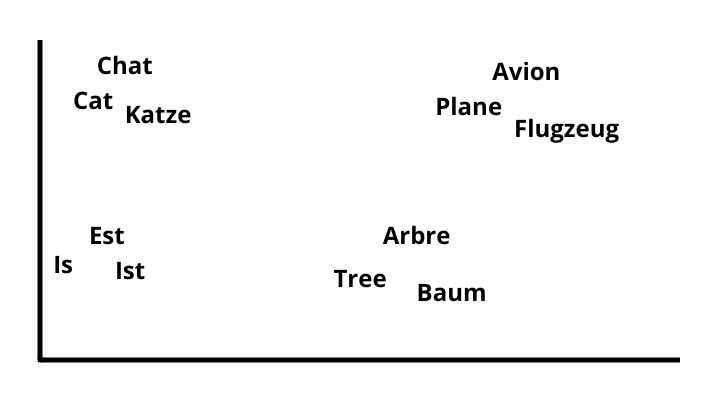
Traduction
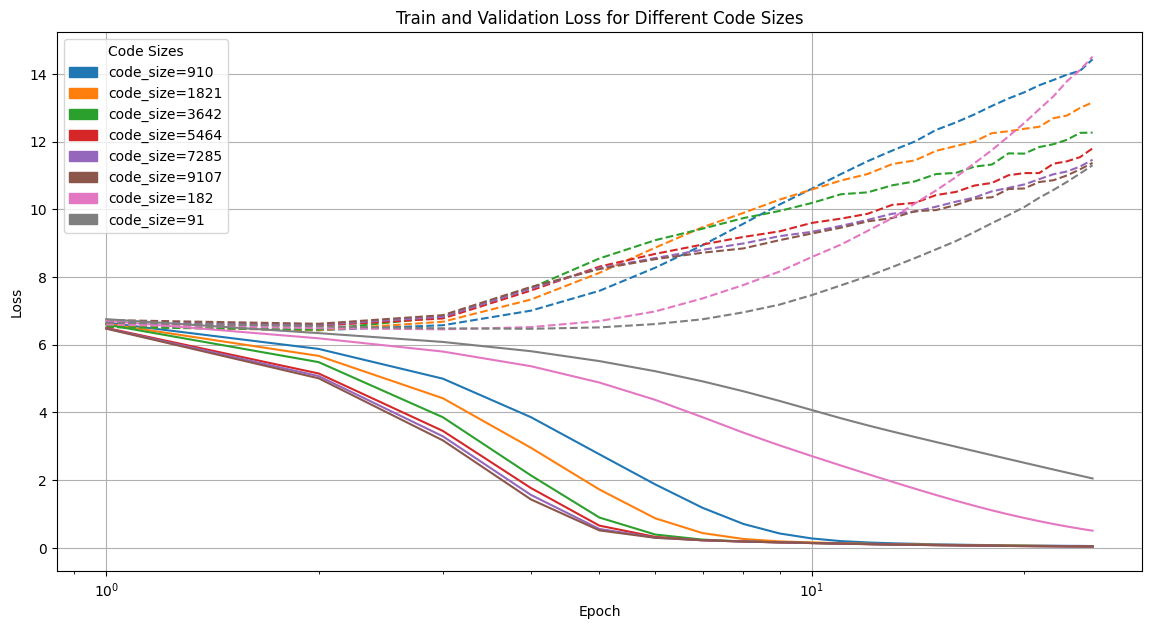
2.4 Performances et comparaisons
Perte en fonction de la taille des représentations latentes
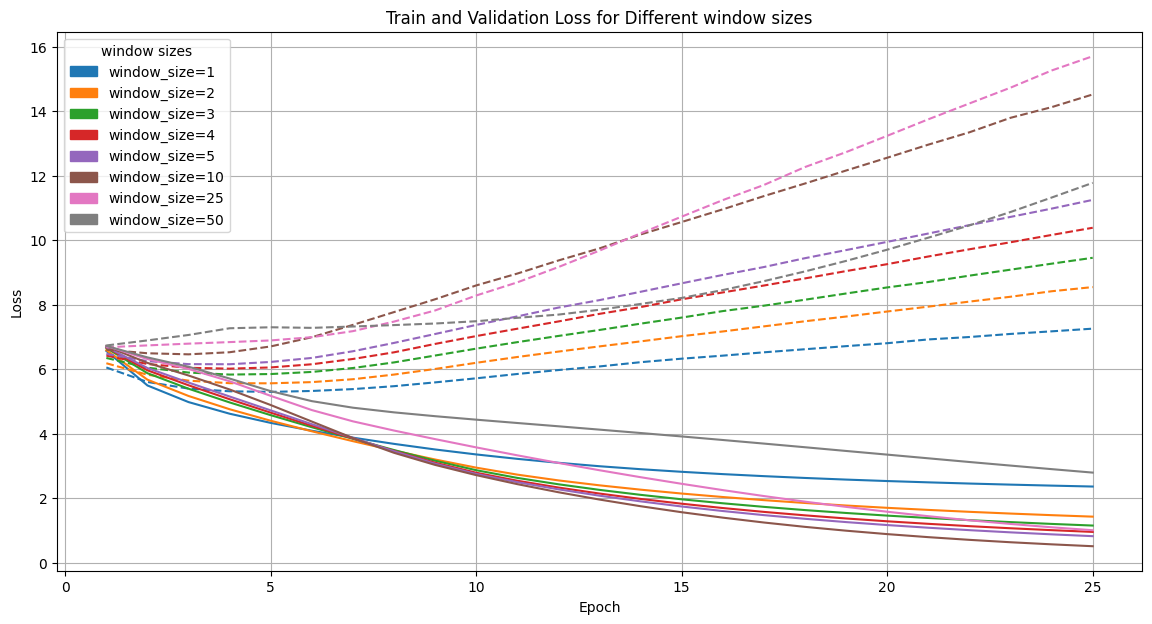
Perte en fonction de la taille de la fenêtre
Mots prédits pour le mot “Paris”
Déductions
- modèle peu performant
- perte des données de validation élevées → suraprentissage ?
- manque de quantité de données ?
- mauvaise représentation des données ?
- mauvaise fonction de perte ?